I lead an automation group where we need to easily spin up and down multiple locally-administered database instances, in support of automated testing of web and other applications. Some applications use MySQL, PostgreSQL or MongoDB, which are supported as Docker Linux Containers. For projects using Windows-based SQL Server, there had been no Container option until the advent of Windows Server 2016, now available in preview (TP5).
To dive immediately into how to create a Dockerized SQL Server, see: Windows Server 2016 Support for Docker Containers.
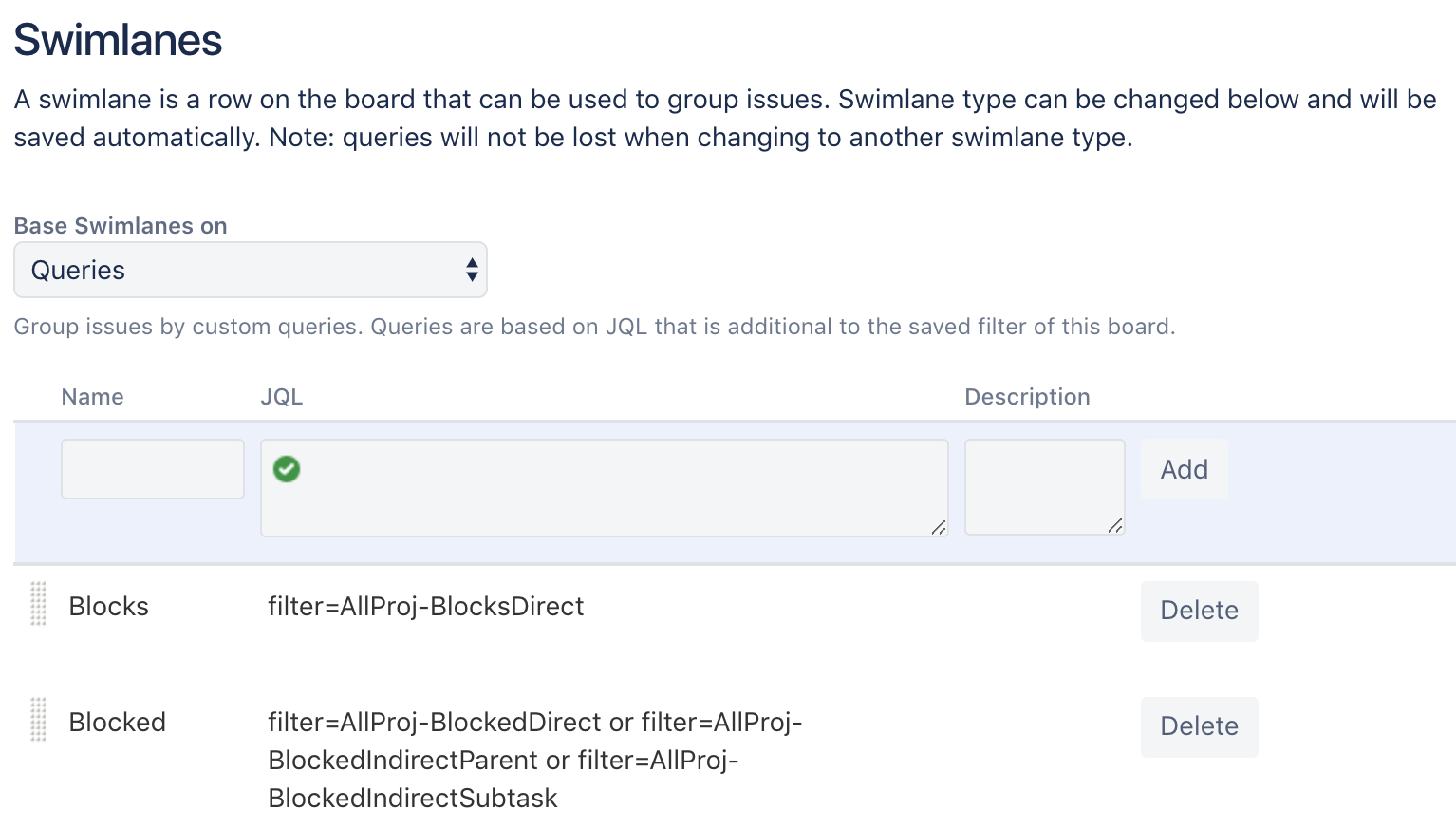
Automation Server Scenario: SQL Server Database Instance private to each test run

The simplified environment diagram above shows how containers are envisioned to be used in the automated build / test environment:
- Docker images are CI-built when source code and / or dockerfile changes (SQL Server image to be rebuilt at most once / week, mainly to pull latest OS and SQL Server updates to image)
- Docker containers are spun up on-demand on a pool of generic VMs – nothing to install on the generic VMs except docker (and build server agent) – no dependency on external sql server instance
- Each test container instance runs against its own dedicated SQL Server container instance, each are torn down at the end of the test
Another scenario – making private SQL Server instances more readily available to Mac developers:
Mac Developer Scenario: SQL Server Local Instance easily installed
Mac Developers, when working on a project using SQL Server, should have access to their own instance of SQL Server. The SQL Server Express Docker image makes that easier – they need only create a Windows Container Host VM (Windows 2016 TP5 preview) using VirtualBox as described here.
Windows Server 2016 Support for Docker Containers
Windows Server 2016 (available now in a preview edition, TP5) introduces support for Windows Containers, with Docker-compatible command support.
Docker Hub currently has Windows Container images for MongoDB, MySQL and SQLite databases (as well as Redis) – but oddly, not for SQL Server.
See below for info on how to build a SQL Server 2014 Express image from a single “docker build” command. It configures SQL Server Express to listen on static port 1433 and supports a runtime choice of data / backups stored internal-to-container or on a host volume. This was created and tested using Windows Server 2016 TP4 Core.
These steps assume you have already established a Windows Container Host VM (with at least 8G free space) – if not see Creating a Windows Container Host VM.
Building the SQL Server Docker image
If you have git installed on the host VM, you can clone the repo https://github.com/bucrogers/Dockerfiles-for-windows.git
Otherwise, pull the files as follows – from powershell:
wget https://github.com/bucrogers/Dockerfiles-for-windows/archive/master.zip -outfile master.zip
expand-archive master.zip
cd master\dockerfiles-for-windows-master\sqlexpress
Build an image named ‘sqlexpress’ using Docker – this will take up to an hour, longer the first time (the Docker Hub base image gets cached in the local Docker repo) – then list the images:
docker build -t sqlexpress .
docker images
Running a SQL Server Docker Container
The firewall on the host VM must be opened for each port to be exposed from a running container, to be accessed outside the host VM – for a single instance of the SQL Server container, open port 1433 – from powershell:
if (!(Get-NetFirewallRule | where {$_.Name -eq "SQLServer 1433"})) { New-NetFirewallRule -Name "SQL Server 1433" -DisplayName "SQL Server 1433" -Protocol tcp -LocalPort 1433 -Action Allow -Enabled True}
Run a single instance of a SQL Express container, in Docker “interactive” mode, with data hosted inside the container – you’ll end up at a powershell inside the container – when you exit powershell the container will stop:
docker run -it -p 1433:1433 sqlexpress "powershell ./start"
Connect using SQL Server Management Studio (I ran this from Windows 10) – you’ll need the hostname / IP address of the Windows Container Host VM (via “ipconfig”). The sa password is ‘thepassword2#’.
Run two SQL Express containers, this time in “detached” mode, with data volumes on the Host VM, first removing the prior container – from powershell:
..\stop-rm-all
md \sql
md \sql2
docker run --name sql -d -p 1433:1433 -v c:\sql:c:\sql sqlexpress
docker run --name sql2 -d -p 1434:1433 -v c:\sql2:c:\sql sqlexpress
You can now connect to either of these from SSMS on their respective ports – when the containers are stopped and removed, the data and any backups remain on the Host VM, to be automatically reused on a future container run.
SQL Server dockerfile details
The dockerfile full source is here. It facilitates the following:
- Configuration of SQL Server Express to listen on static port 1433
- Installation from SQL Server 2014 Express download link
- -or- Provided SQL Server edition setup.exe
- Run with data / backups inside the container (not persisted)
- -or- Data / backups on host VM (persisted)
- Bootstrap first-time data initialization for persisted mode
- Running container either detached or interactive
Below is a walk-through of the key statements in the dockerfile:
Use a base image from Docker Hub including .NET Framework 3.5, since SQL Server requires it – the first time this is run, it will download to the local Docker registry running on the host, after which it is pulled from the local registry:
FROM docker.io/microsoft/dotnet35:windowsservercore
Declare Docker environment variables for data folder usage etc. – these may be overriden at container-runtime (though that is not useful for this image):
ENV sqlinstance SQL
ENV sql c:\\sql
ENV sqldata c:\\sql\\data
ENV sqlbackup c:\\sql\\backup
Copy files from host into container for use at build time:
COPY . /install
Download SQL Server 2014 Express installer from link and extract files to expected setup folder (this link may be customized for any other edition of SQL Server, or the dockerfile may be modified to copy existing setup\* files from the host) :
RUN powershell invoke-webrequest http://download.microsoft.com/download/E/A/E/EAE6F7FC-767A-4038-A954-49B8B05D04EB/Express%2064BIT/SQLEXPR_x64_ENU.exe" \
-OutFile sqlexpr_x64_enu.exe
RUN /install/sqlexpr_x64_enu.exe /q /x:/install/setup
Run SQL Server installer, specifying folders, sa password, TCP protocol enabled – special note: the SYSTEM account must be used for the SQL Server Engine service as of Windows 2016 TP4 (the default “Network Service” account does not work):
RUN /install/setup/setup.exe /q /ACTION=Install /INSTANCENAME=%sqlinstance% /FEATURES=SQLEngine /UPDATEENABLED=1 \
/SECURITYMODE=SQL /SAPWD="thepassword2#" /SQLSVCACCOUNT="NT AUTHORITY\System" /SQLSYSADMINACCOUNTS="BUILTIN\ADMINISTRATORS" \
/INSTALLSQLDATADIR=%sqldata% /SQLUSERDBLOGDIR=%sqldata% /SQLBACKUPDIR=%sqlbackup% \
/TCPENABLED=1 /NPENABLED=0 /IACCEPTSQLSERVERLICENSETERMS
Change TCP protocol configuration to listen on static port 1433, since SQL Server Express defaults to a dynamic port:
RUN powershell ./Set-SqlExpressStaticTcpPort %sqlinstance%
Remove the data and backup directories, in order to facilitate running this image with data and / or backups hosted either internal-to-container or on an external volume.
This is necessary since Windows Docker, as of TP4, does not support mapping to an existing container folder. But even when that support is added, it may be preferable to leave this as-is since this approach supports a first-time automatic “bootstrap” copy of data files to an external host volume:
RUN powershell ./Move-dirs-and-stop-service %sqlinstance% %sql% %sqldata% %sqlbackup%
Declare a default CMD, which simplifies invoking “docker run” later – this first invokes start.ps1 to setup files appropriately for an internal or external data volume, then runs a detached-friendly sleep loop:
CMD powershell ./start detached %sqlinstance% %sqldata% %sqlbackup%
Creating a Windows Container Host VM on Azure
See here for an example Azure Resource Template to create a Container-ready Windows Server 2016 TP5 VM on Azure.
Creating a Windows Container Host VM on Hyper-V
The following instructions are adapted from Deploy a Windows Container Host to a New Hyper-V Virtual Machine:
Prerequisites
You may run a Windows Container Host VM on any of the following (I performed my testing on both Windows 10 and Azure):
Steps
Open Command Prompt (Admin), then start powershell:
powershell
Determine if a VM Switch is configured – if nothing returned below, create a new *external* VM switch then proceed:
Get-VMSwitch | where {$_.SwitchType –eq “External”}
Pull the create container host script
Important note: modify this before running to increase disk size from 8G to 20G by searching for “-SizeBytes 8GB”>
wget -uri https://aka.ms/tp5/New-ContainerHost -OutFile c:\New-ContainerHost.ps1
Run the script to create the Container Host VM – this will take up to 1.5 hrs. Note there is an optional “-Hyperv” argument which will work only if running on Windows 2016 TP4 installed on a physical box – this is necessary only to evaluate “Hyper-V Containers”, not for “Windows Containers”:
c:\New-ContainerHost.ps1 –VmName <yourVmName> -WindowsImage ServerDatacenterCore
If you get a “running scripts is disabled” error, then execute the following then try again:
Set-ExecutionPolicy RemoteSigned
References