

General QA
Pyramid / test categories
Testing in Production
Distributed / Complex System testing
Oracles and Simulation
Fakes and Mocks
Test Data Mgmt.
Other Test Patterns
Agile testing
Exploratory Testing
Unit Testing
API Testing
Regression Testing
UI-specific testing
UI-specific testing selenium-specific
Performance testing
Penetration / security testing
Server testing
Test Automation
Bug Mgmt
Lists
- Jeff Nyman: Testers: Act like a developer – develop something; programming (e.g., for just automation) and development are not the same thing
- Mosaic: Peter Wilson: Ten Common Mistakes Companies Make Setting Up and Managing Software Quality Assurance Departments – this article advocates for qa driving not just qa but also overall process; the ten: 1) not properly defining objectives; 2) not properly defining qa’s responsibilities and staffing; 3) sr. mgmt. not understanding their responsibility for qa; 4) not holding the qa dept. accountable for proj success; 5) assuming existing standards / processes are followed and are sufficient; 6) separating methodology responsibilities from review and enforcement; 7) not integrating measurement into process; 8) ignoring, misunderstanding or not communicating risk; 9) lack of mgmt. reporting from qa; 10) qa dept. positioned to low in the org
- EvilTester.com: blog on Exploratory, Selenium, Technical testing etc.
- Josiah Renaudin: Is the “Traditional Tester” Just a Myth? – most good testers already had at least some dev skills – the need for this has only increased with agile short cycles and the need for automated regression testing to support a build pipeline
- Jeff Nyman: Testing, Integration, and Contracts – Part 1 – the testing ‘lozenge’ instead of the triangle (with an integrat* nougat center) ; integrated vs integration; edge-to-edge as a way to more intuitively describe contract testing, good distinction from end-to-end testing. part 2 – Fowler: “An integration contract test is a test at the boundary of an external service verifying that it meets the contract expected by a consuming service”;
- Smart Bear / Pactflow: Contract Testing vs. Integration Testing – “A contract test is completed in isolation, between only one API consumer and one provider. It doesn’t check for side effects, or the behavior of the overall system”; “integration tests look for information on how two or more systems work together. They’re a form of functional testing that ensures all features continue to work as expected after a change has been introduced”; “Contract testing … the way it works is to borrow elements of both unit and integration testing”
- Ham Vocke: The Practical Test Pyramid – Unit (mocking and stubbing); Integration (db, with separate services); Contract (consumer, provider, tests); CDC (Consumer-Driven Contract tests); Pact tool for CDC
- Ian Robinson: Consumer-Driven Contracts: A Service Evolution Pattern – provider contracts; consumer contracts; consumer-driven contracts
- Thoughtworks: Testing Strategies in a Microservice Architecture – definitions, testing strategies, Test Pyramid quantifications, environment isolation; contract testing defined
- Thoughtworks: Consumer-driven Contracts: A Service Evolution Pattern – “just enough” validation strategy; contract testing assertions
- James Bach: Six Things That Go Wrong With Discussions About Testing – 1) When people care about how many test cases they have instead of what their testing actually does; 2) When people speak of a test as an object rather than an event; 3) When people can’t describe their test strategy; 4) When people talk as if automation does testing instead of humans; 5) When people talk as if there is only one kind of test coverage; 6) When people talk as if testing is a static task that is easily formalized; “Through these and other failures in testing conversations, people persist in the belief that good testing is just a matter of writing ever more “test cases” (regardless of what they do); automating them (regardless of what automation can’t do)”
- Martin Fowler: TestPyramid – Basic intro to the test pyramid concept
- Google Testing Blog: Mike Wacker: Just Say No to More End-to-End Tests – case-study-driven comparison between unit, integration and E2E, illuminates the weakness of over-reliance on E2E including slower feedback loop to developers; good definition of integration tests
- Friendly Tester: GUI Automation Tweet – GUI Check/Test #Automation is not bad. Thinking automation = GUI T/C automation is. Only have GUI T/C automation could be.
- Bradshaw & Stevenson: A Look At The “Test Automation” Pyramid (10min vid) – automation is “tool-assisted” testing; automated checks are artifacts of testing; ice cream antipattern is actually (manual testing flavored) ice cream throughout the cone not just at the top; they are one thing, automation and manual testing, not manual testing only at the cloud (manual) level
- John Stevenson: Test Execution Model (4min vid) – different take on pyramid – toward top of pyramid is more unknown unknowns driven out by more testing; toward bottom, more known known driven by more checks; testers need to regulate the number of tests they create by their biz value, don’t just write them because they are easy
- Google Testing Blog: Simon Stewart: Test Sizes – Small / Medium / Large as an alternative to the often-misunderstood terms unit / integration / E2E
- WatirMelon: 100,000 e2e selenium tests? Sounds like a nightmare! Describes the key weaknesses in having too many slow UI e2e tests
- Rob Lambert: Tester Types – Enforcer; Drama Queen; Comedian; Magician; Chuck Norris; Explorer; Checklister; Sage; Socializer; Day Dreamer; Boss; Automator; Wanderer; Micromanager; Nitpicker; Expert; Drafter; Networker; Intellectual
- James Crisp: Automated Testing and the Test Pyramid – Argues for minimizing use of executable specs / traceability / automated acceptance UI tests
- Velocity Partners: The Agile Test Automation Pyramid
- Thoughtworks: Introducing the Software-Testing Cupcake (Anti-Pattern) – Shows both the anti-pattern and the more desired pyramid
- WatirMelon: Introducing the software testing ice-cream cone (anti-pattern) – First shows a GUI/API/Integration/Component/Unit pyramid, then ice-cream
- HYPOPORT IT: An AngularJS Test Pyramid (Unit -> Directive -> Scenario -> Selenium)
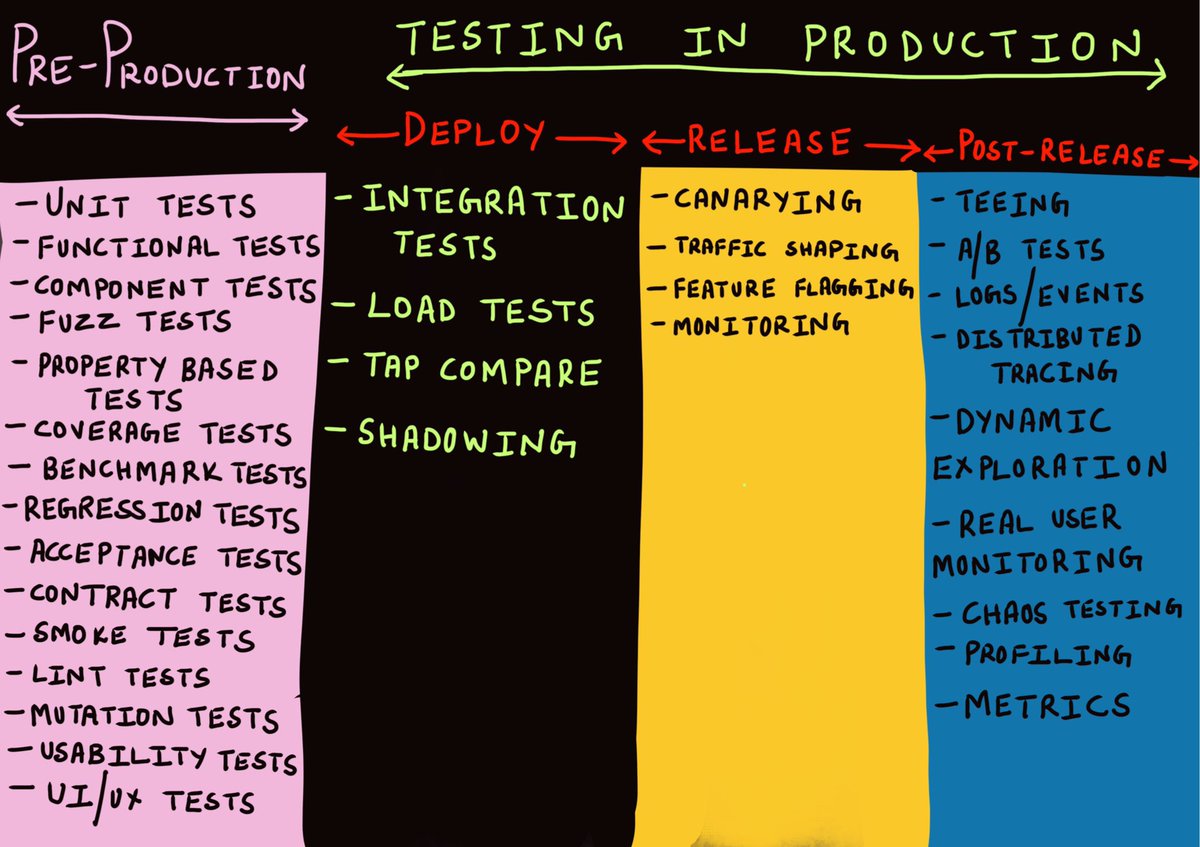
- Cindy Sridharan: Testing in Production (infographic) – Pre-Production (Unit, Functional, Smoke, Contract et al.) -> Deploy (Integration, Load et al.) -> Release (Canarying, Feature-flagging, Monitoring) -> Post-Release (A/B, Logs / Events, Dynamic Exploration, Real User Monitoring, Chaos Testing et al.)
- Cindy Sridharan: Testing in Production: the hard parts – “Testing in production allows for the verification of the twin aspects of system design: if the test passes, it helps improve confidence in the robustness of the system, and if the test fails, one can end up exercising (and thereby testing!) mitigation strategies to restore the service back to health, which helps build confidence in the effectiveness of some subset of one’s disaster recovery plans. This ensures that service restoration is an effort undertaken regularly and not just during a widespread outage. In a manner of speaking, preparedness and general disaster recovery competence becomes a prerequisite (and not just something co-developed) when testing in production.”; Safe and Staged Deploys; Quick Service Restoration; To Crash or Not to Crash; Change One Thing at a Time; Divorce the Control Plane from the Data Plane; Eschew Global Synchronized State
Distributed / Complex System testing
- Thoughtworks Technology Radar: Enterprise-wide integration test environments – HOLD; “Testing in the staging environment provides unreliable and slow feedback, and testing effort is duplicated with what can be performed on components in isolation. We recommend that organizations incrementally create an independent path to production for key components. Important techniques include contract testing, decoupling deployment from release, focus on mean time to recovery and testing in production.”
- Caitie McCaffrey: The Verification of a Distributed System: A practitioner’s guide to increasing confidence in system correctness – Distributed systems are difficult to build and test for two main reasons: partial failure and asynchrony; Asynchrony is the nondeterminism of ordering and timing within a system; essentially, there is no now; Partial failure is the idea that components can fail along the way, resulting in incomplete results or data; Without explicitly forcing a system to fail, it is unreasonable to have any confidence that it will operate correctly in failure modes;
While monitoring the system and detecting errors is an important part of running any successful service, and necessary for debugging failures, it is a wholly reactive approach for validating distributed systems; bugs can be found only once the code has made it into production and is affecting customers. All of these tools provide visibility into what your system is currently doing versus what it has done in the past. Monitoring allows you only to observe and should not be the sole means of verifying a distributed system; Incorrect error handling of nonfatal errors is the cause of most catastrophic failures; Unit tests can use mock-ups to prove intrasystem dependencies and verify the interactions of various components. In addition, integration tests can reuse these same tests without the mock-ups to verify that they run correctly in an actual environment; The bare minimum should be employing unit and integration tests that focus on error handling, unreachable nodes, configuration changes, and cluster membership changes; Fault Injection; Netflix Simian Army - Philip Maddox: Testing a Distributed System (ACM subscr.) – focus on distributed data storage systems; component tests plus E2E data delivery tests; simulators can be helpful but beware of their limitations; two of the most difficult distributed data issues are asynchronous data delivery and node failure; parallel testing pros and cons
- Adrian Colyer: Growing a protocol – (analysis based on the linked longer paper of the same name); “how best to implement and evolve distributed system protocols without introducing unintended bugs”; “tool support for implementing and evolving fault-tolerant distributed systems needs to be rethought. We advocate exploration of the (sparse) middle ground between existing testing techniques practically inadequate for addressing fault tolerance concerns and traditional verification techniques ill-suited to the continual evolution of real-world evaluations”; also references Use of Formal Methods at Amazon Web Services; “”regression testing techniques ensure future optimisations do not re-introduce bugs previously encountered in early stages of system development”. In regression testing we check that inputs known to result in bad behaviour in the past no longer do.”; “In the ideal case, the team would be using some kind of formal verification, and specifications would be co-evolved with the code and invariants proved afresh. In practice, this rarely happens. The correctness guarantees determined at initial verification time erode as protocols evolve”; “…regression testing alone is not sufficient to assert fault tolerance properties. Inputs that trigger bugs in one version of a protocol are not guaranteed to trigger the same bug in a different version. In distributed systems, a large class of bugs are tied to the execution schedule, not (just) to the inputs”; “regression testing, as we currently employ it, is fundamentally too weak to prevent fault tolerance regression bugs. Root cause analysis is similarly inadequate, because a set of faults triggering bugs in later versions may fail to do so in an earlier version”; “Elastic engaged our research team because they wanted a technique that strikes a balance between formal verification and testing – in particular the strong correctness guarantees of the former and the agility of the latter. The project used Lineage Driven Fault Injection (LDFI), which builds a model based on good system execution and explores only fault scenarios capable of forcing the system into a bad state”
- Bill Wake: Testing with Simple and Combinatorial Oracles – “I refer to oracles that have to account for many possible results as combinatorial oracles“; techniques: Simple; Limiting Solutions; Accounting for Possibilities; Subsetting Possibilities
- Cem Kaner: The Oracle Problem and the Teaching of Software Testing – “oracles are necessarily incomplete”; “”oracles are heuristics”; “bach / bolton consistency heuristics”; “doug hoffman’s approach” (to using oracles in test automation);
- Martin Fowler: TestDouble – Dummy, Fake, Stub, Spy, Mock types
- Martin Fowler: SelfInitializingFake
- Joel Quenneville: Faking APIs in Development and Staging – using ruby/sinatra to implement fakes, including async solution
- Shawn Conlin: How to lift your test automation game: Tame your data – data strategy patterns: elementary, refresh, selfish
- Friendly Tester: An Introduction To The Data Builder Pattern – model, builder, creator (abstracts db impl.), db (serves as cache built up over time on-demand)
- James Shore: Testing Without Mocks: A Pattern Language – “This pattern language describes a way of testing object-oriented code without using mocks. It avoids the downsides of mock-based testing, but it has tradeoffs of its own”; Goals: No broad tests required; Easy refactoring; Readable tests; No magic; Fast and deterministic; “These patterns are an effective way of writing code that can be tested without test doubles, DI frameworks, or end-to-end tests.”
- Twitter engineering: The testing renaissance (feature testing) – “A test verifying a service or library as the customer would use it, but within a single process”; “The end purpose of feature tests is generally much clearer than individual unit tests.”; “Testing from customer point-of-view – Leads to better user APIs”
- Johanna Rothman: What do Agile Testers look like? – “… the kind of system-level testing that says “Does this feature meet its acceptance criteria, and does the rest of the system still work and can we know that within a two-week timebox?” is not primarily manual testing. That’s what agile projects need.”
- Aaron Hodder: Phased vs Threaded Testing – Phased: reqts -> scripting / test cases -> Execution -> Exit / Reporting; Threaded is more concurrent: Learning, Modeling, Evaluating, Feedback
- The Essence of Testing: Interview with Exploratory Testing Expert & Philosopher, James Bach, Part 1, Part 2, Part 3 – Part 1: Essence of testing; Part 2: Throwing away ‘Bad Software Testing’ with Agile and RST; Part 3: Testing Tools vs. Test Automation
- Kathryn Nest: The Value of Risk-Based Testing From an Agile Viewpoint – “… I listed risks associated with each user story, giving out numbers for probability and impact and then multiplying the two to get the risk priority number (RPN)…”; “This approach helps in task allocation because we know where to focus our test efforts and limited time on the maximum value areas so they can yield the best outcomes—all without adding overhead, cumbersome process or tasks”
- Matt Heusser: Programmer / Tester Pair Programming
- Martin Fowler & Manasi Kulkarni: Agile Fluency and Testing (1hr12m vid)
- Michael Bolton: Drop the Crutches – “Test cases are formally structured, specific, proceduralized, explicit, documented, and largely confirmatory test ideas. And, often, excessively so”; “The idea that we could know entirely what the requirements are before we’ve discussed and decided we’re done seems like total hubris to me”; “Instead of overfocusing on test cases and worrying about completing them, focus on risk. Ask “How might some person suffer loss, harm, annoyance, or diminished value?”
- Shift Left but Get It First-Time Right: An Interview with Shankar Konda – “shift left is more about how we accelerate the development activity in conjunction with the testing processes”; “moving away from a shared services model like the test center of excellence to a more federated model of testing, where quality assurance and testing teams work collaboratively with the development teams”; “Automation which used to happen at the end of the testing lifecycle is now a thing of the past. Now we are talking about how progressive automation, or holistic automation across the lifecycle, can enable the development teams to accelerate the process to integrate”; “explore a test-driven development approach by integrating QA with the agile teams with early creation and execution of automation test scripts”; “gone are those days where the traditional model of testing was as a gatekeeper. In the good old days, you are trying to find a defect, and once you find a defect, you’re expecting to get it repaired, and then you try to retest that repair and to see if the defect doesn’t exist anymore—so traditionally, it was more of a quality control function… the market is not accepting that kind of methodology anymore… In the modern era, what is happening now is testing is not just testing anymore—it is more quality engineering now. It is more how quality can be engineered into the practices of the development lifecycle itself. In fact, for a couple of our customer engagements, TCS has redefined the roles of the quality assurance and testing professionals. They are now being referred to as “quality engineers” instead of quality analysts. They’re not any longer just testers because of the fact that they need to enable the other aspects of lifecycle development and become that part of the development team. They are not just part of the testing team anymore; they are part of the development team, working as quality engineers”; “expecting the quality team to perform an anchor role in getting things done. They don’t want them to be over the fence and telling other people that something is wrong. They want something to be anchored and help facilitate between the teams and get things done without raising a red flag, so the anchor role is now between the development teams, the business, and the operations”
- Atlassian: Quality at Speed (30min video + transcribed Q&A on Atlassian’s “Quality Assistance” approach)
- Shalloway, Beaver, Trott: Lean-Agile Software Development: The Role of Quality Assurance in Lean-Agile Software Development – role of testers to prevent defects, not find them; two lean principles: build quality in, eliminate waste; use found defects to improve process; QA at the end of the cycle is wasteful; team benefits from spec’d tests upfront even if not yet automated
- Gary Miller: From Test Cases to Context-Driven: A Startup Story (1h15m vid) – references heuristic approaches by Bach, Kendrickson, Johnson and how he applied them to evolve an approach and shorten release cycles
- Gregory & Crispin: Using Models to Help Plan Tests in Agile Projects – book chapter – Modeling test planning using Agile Testing Quadrants, Nonfunctional requirements, Test automation Pyramid
- Amy Reichert: Use manual modular tests for testing automation development – architecting tests in a modular fashion leads to more maintainable tests; starting with manual testing of modules then automating later often makes sense; cleaner test architecture avoids the pile-of-hard-to-maintain-tests syndrome
- Bill Wake: Resources on Agile Testing
- Keith Klain: qualityremarks blog
- #ShiftLeft
- Ingo Philipp: Exploratory Testing: Expanding Testing Across the Delivery Cycle – Exploratory testing in action: Perform Ad Hoc Exploratory Testing as Each User Story is Implemented; Align Exploratory Testing Sessions with Full Regression Testing; Host Blitz Exploratory Sessions for Critical Functionality
- Simon Knight: 3 Ways to Plan Testing – Risk-based Test Planning, Session-Based Test Mgmt., Heuristic Test Strategy model;
- Simon Schrijver: Session-Based testing for Agile Projects (sketchnote) – One-page sketch showing Session Types, Artifacts, typical path
- Jess Ingrassellino: Everyday Agile Practices for Every Tester – “Session-based testing (allotting a specific amount of time, or a session, in which to complete an exploratory test), or test charters (a way to document the details of an exploratory test session), are ways to reduce documentation while still maintaining the desired level of testing evidence”
- Jeff Nyman: Manual Testing Deniers – does the term “manual testing” exist? if so, is it a useful term?
- Owen Strombeck: Exploratory Testing Tips – perspectives from 4 different QEs
- When to use Exploratory Testing and What it Gives as Compared to Scripted Testing – pros and cons, when to use
- SmartBear: Exploratory vs. Scripted Testing: One or the Other, or Both? – “How can you create plans that focus your exploration while remaining flexible?”; test charters; session-based testing; mind maps
- James Bach: Why Scripted Testing is Not for Novices – … unless you want bad testing; “Both on the design side and the execution side, scripted testing done adequately is harder than exploratory testing done adequately”; “The reason managers assume it’s simpler and easier is that they have low standards for the quality of testing and yet a strong desire for the appearances of order and productivity”;
- Bach & Bolton: Testing and Checking Refined – Testing is exploratory, heuristic, done by humans; Checking by machines, algorithm-based
- Michael Bolton: Testing Problems are Test Results -“…testing is, as Jerry says, gathering information with the intention of informing a decision…”; “We often run into problems when we test. But instead of thinking of them as problems for testing, we could also choose to think of them as symptoms of product or project problems—problems that testing can help to solve”
- Bolton & Bach: A Context-Driven Approach to Automation in Testing – distinguish between checking and testing; invest in tools that give you more freedom in more situations; invest in testability
- Kaner & Bach: Context-Driven-Testing – The Seven Basic Principles of the Context-Driven School
- James Bach: Exploratory Testing Explained – Shorter version: What is Exploratory Testing? – Concurrent Test Design and Execution; Balancing Exploratory with Scripted; Why Do Exploratory?
- Rob Lambert: Managing Exploratory Testing – exploratory test charters; storing charters in confluence; reporting
- WatirMelon: Testing beyond requirements? How much is enough? Three Amigos User Story Kick-Offs, Exploratory Testing
- Bach: Heuristic Test Strategy Model – heuristic test patterns for designing a test strategy; given product elements, project environment, quality criteria, this defines the general test techniques / heuristics for creating tests, leading to perceived quality (the result of testing)
- Bach: Low-tech Testing Dashboard – simple table to show status and relative confidence in various areas
- Hendrickson: Test Heuristics Cheat Sheet – testing wisdom, attacks, heuristics, frameworks
- Santhosh Tuppad: Software Testing – Heuristics Cheat Sheet – references Michael D Kelly (Touring Heuristics, Test Reporting Heuristics); Ben Simo (Error Handling Heuristics); Scott Barber (Performance Testing Heuristics); Adam Goucher (Ordering of Testing Tasks Heuristics); James Bach (Quality Criteria, Learning, Test Techniques, Project Environment, Test Strategy Heuristics, Test Oracles)
- Karen Johnson: Software Testing Heuristics & Mnemonics – regression RCRCRC: Recent Core Risky Configuration Repaired Chronic
- Keith Klain: Talking with C-level Management about Testing (25min vid) – talking about testing alignment with biz strategy, what you want them to know / do
- Anne-Marie Charrett: Models & Software testing (3min vid) – mental (existing product test world), formal (e.g., state transition diagrams, requirements), physical (e.g., test env. itself); create models to get an understanding; reading, asking (e.g., whiteboard session with product owner and others), doing (exploratory); what am i missing? testing is about learning
- Justin Rohrman: The Reality of Test Artifacts – challenges value of test cases, points out misleading metric of # of test cases – he is referring here more to the danger of relying only on ‘scripted test cases’, not the need for doing testing with at least a skeleton ‘test case’
- Michael Bolton: The End of Manual Testing – 7 kinds of testers: developer, technical tester, administrative tester, analytical tester, social tester, emphatic tester, user expert; “let’s recognize and admire technical testers, testing toolsmiths and the other specialists in our craft. Let us not dismiss them as “manual testers”
- James Bach: Testing vs. Checking blog posts
- Gill Zilberfeld: Everyday Unit Testing – Creating a unit test strategy; “This approach works for both TDD and test-after, but it works well where most of the systems are legacy mode”
- Steve Berczuk: The Value of Testing Simply – “too many low-value tests can slow integration time, lengthening the feedback cycle that makes agile work”; “tests that cover more code (see Ruberto article below) don’t always improve quality. Some tests have low value and thus, implicitly, high cost”; “when it comes to testing, the line between trivial and valuable can be a fine one. If you err too much on the side of seemingly complex testing, you may lose opportunities to find and fix problems early”; “Validating that configuration files are syntactically correct and that the code in your persistence layer is mapping all the essential fields in the data store seem like the kinds of errors one could catch by inspection, but we don’t always do so”; “any validation you can do as part of your build pipeline helps you fix the problems earlier and at lower cost. Some research even shows that simple testing using validation and static analysis can prevent most critical failures (see Colyer article below)”
- Adrian Colyer: Simple testing can prevent most critical failures – “the more catastrophic the failure (impacting all users, shutting down the whole system etc.), the simpler the root cause tends to be”; “Almost all catastrophic failures (48 in total – 92%) are the result of incorrect handling of non-fatal errors”; “In 23% of the catastrophic failures, while the mistakes in error handling were system specific, they are still easily detectable. More formally, the incorrect error handling in these cases would be exposed by 100% statement coverage testing on the error handling stage”; “Almost all (98%) of the failures are guaranteed to manifest on no more than 3 nodes. 84% will manifest on no more than 2 nodes…. It is not necessary to have a large cluster to test for and reproduce failures”
- John Ruberto: 100 Percent Unit Test Coverage is not Enough – “One hundred percent unit test coverage doesn’t say anything about missing code, missing error handling, or missing requirements”; “The unit tests will check that the code is working as the developer intended the code to work, but not necessarily that the code meets customer requirements”; “Having the code 100 percent executed during testing also does not mean the tests are actually good tests, or even test anything at all”; “Unit testing is a fantastic way to test exception handling because the developer has full control of the context and can inject the conditions necessary to test the errors”
- James O Coplien: Why Most Unit Testing is Waste
- (book) Osherove: The Art of Unit Testing: with examples in C# – Clear explanations of fakes, mocks, stubs
- Justin Rohrman: Getting Started With API Testing For Fun & Profit – tools Postman (to explore) and Airborne / rspec (to automate); “People tend to associate technical testing with building automation, but for me, testing always starts with exploration”; Trello board automation example
- Guru99: Learn API testing in 10 minutes!!! – Difference between API testing and Unit testing table; What to test for in API testing; Best Practices of API testing
- Justin Rohrman: Language in Software Testing – good overview of what ‘regression testing’ can mean to various parties: “…the real smoke test was at the intersection of all their desires. Our product managers wanted something that would represent the most important functionality in our product for a handful of highly profitable customers. These were scenarios that must work for our customers to be able to do their job. Within the test group, we wanted coverage that would find important bugs. These were severe failures that would reduce the value of our software for large groups of people. That might be a browser crash, or a data persistence problem, or just an image overlapping a submit button on a webpage.What our manager really wanted, was to avoid the question of “why wasn’t this tested?” and also have the smoke test performed quickly, using as few people for as little time as we could get away with. What we ended up with was a set of 10 or so scenarios built as automated user interface tests. These ran against candidate builds toward the end of each release and took about 15 minutes to finish”
- Martin Fowler: Eradicating non-determinism in tests – quarantine; lack of isolation; async behavior; remote services; time; resource leaks
- Friendly Tester: Flawed Approach to Regression Testing (FART) (12min vid) – 3 layers of a SUT: system -> knowledge -> checks; need to regularly review automated test suites; think of automation as change detection; balance increasing automated checks with need to increase knowledge (via exploratory) – related interview write-up
- Friendly Tester: How Often Do You Really Fix A “Failing” Automated Check – regularly review automated checks, ensure they are adding value
- Jon Bellah: Visual Regression Testing with PhantomCSS – things like CSS changes are particularly likely to result in dramatic breakage; humans’ change blindness limits their effectiveness manually testing for visual regressions; handling dynamic content via static content JavaScript injection; checking vs. testing
- Dave Haeffner: How to Handle Visual Testing False Positives
- Justin Rohrman: Consider “Reasonable” UI Test Automation – case study of adding ‘shallow’ tests to legacy app, supplementing this with log analysis of failures
- LinkedIn: Keqiu Hu: How we make UI tests stable – possibly questionable approach to UI testing almost seems overly mocked, but interesting; 700 UI Tests and 1,000 Unit tests running stably and swiftly; flaky tests were worse than no tests. In other words, if a test wasn’t stable, we would rather eliminate it from our test suite; how can we make UI tests stable? flaky testing environment; flaky testing framework; flaky tests; trunk guardian
UI-specific testing selenium-specific
- Groupon: Dima Kovalenko: Selenium-Grid-Extras – helper utilities to simplify the managment of the Selenium Grid Nodes and stabilize said nodes by cleaning up the test environment after the build has been completed
- Groupon: Dima Kovalenko: Scaling and managing Selenium Grid (48min vid) – using Selenium-Grid-Extras (above), slides here
- Groupon: Dima Kovalenko: Black Hole Proxy for Selenium Testing
- Dave Haeffner: How to Do Visual Testing with Selenium – lists available visual-comparison tools including those which work for Selenium
- Dave Haeffner: Essential Selenium: Tips
- Friendly Tester: Webdriver beyond Checks – idea: compare tables by writing out html and processing that, rather than selenium-nav’ing every cell
- Carlos Becker: Running a Selenium Grid with docker-compose – use docker compose for scalable selenium cluster for firefox, chrome
- SeleniumHQ: InternetExplorerDriver wiki page – “Attempting to use IEDriverServer.exe as part of a Windows Service application is expressly unsupported. Service processes, and processes spawned by them, have much different requirements than those executing in a regular user context. IEDriverServer.exe is explicitly untested in that environment, and includes Windows API calls that are documented to be prohibited to be used in service processes”
- [selenium-users] IEDriverServer.exe is not supported as windows service, how do you auto start your grid node?
- Noam Manos: Windows auto logon configuration via AutoLogon.reg – ” If you’re getting black screenshots or other GUI problems (when using Selenium, Test Complete, etc.), then create a batch file that disconnects Remote Desktop, instead of closing the RDP session with the regular X button”
- Dima Kovalenko: Agile Software Testing: Selenium articles
Penetration / security testing
- Ronnie Flathers: Docker for Pentesters – “… Docker containers as fast, purpose built, disposable environments for testing things and running applications”; Useful Docker Aliases; Example 1 exploring other OSs; Example 2 Compiling code for old targers; Example 3 Impacket; Example 6 Serving Files behind NAT with Ngrok; Example 9 -Capturing HTTP Files; Bonus Example Windows Containers
- aelsabbahy: Tutorial: How to test your docker image in half a second – “test driven infrastructure”; declarative testing of docker images using lightweight Goss framework
- Paul Holland: The Pothole of Automating too Much (sketchnote)
- Deliberate Testing in an Agile World: An Interview with Dan North – “Most of the teams I work with who would describe themselves as agile tend to have two types of testing: automated feature and unit testing, and manual exploratory testing.. it’s almost embarrassing how many types of testing we aren’t even aware of; never mind whether or not we are choosing to do them”; “…the idea of testing teams itself is flawed. Testing is a set of capabilities that should be intrinsic to any software delivery team, rather than something handed off to a dedicated testing team”
- Richard Bradshaw: A look at test automation and test automators – responses to tweets by Alan Page; difference between Automation In Testing and Test Automation; devs should be primarily writers of test automation
- Dave Nicolette: When to Stop Testing – review of linked Simon Knight: When do I stop Testing article; testing or checking; stopping heuristics; “specifications shouldn’t be the beginning and end of testing”
- Richard Bradshaw: Automation In Testing – blog
- Justin Rohrman: The Bug Reporting Spectrum – “…boring triage meetings, where managers decide what is or is not a bug”; “use the title format ‘X fails when Y’”; “If the steps to reproduce the bug were needed, they focused on the parts that were critical”; “I reduced the amount of written bug reports by at least 50%”; “Bug reports were mostly done through demonstration and conversation. We were able to discover new problems, demonstrate exactly how they were triggered, and get them fixed without ever touching a bug tracking system. We went to the bug tracker only when we had questions that couldn’t be answered immediately, or bugs that were complicated and needed some research before they were fixed”; “The idea of “zero defects” is a lie… At some point during feature development, a tester, programmer, or product person will stumble across a problem that can’t be fixed immediately. That issue might be complicated, it might require research, or the programmer may be busy working on something else. Either way the bug can’t be fixed now, and not documenting it is risky business”; “My general rule now is to only make a bug report when it’s an absolute necessity. If there is a question that no-one can answer in the next day, or if there is a bug that can’t be fixed yet. Most of the time, I find that a conversation can solve problems that a bug report introduces”; “Some people say the best tester is the one that finds the most bugs. I’d change that and say the best tester is the one that can get the most bugs fixed. That means reporting them in a way people care about and understand”
- Melissa Eaden: When Testers Deal With Process Debt: Ideas to Manage It And Get Back To Testing Faster – warning signs of process debt; example of a good defect management plan; tips for cleaning up test cases; consolidating and maintaining documentation; the devil is in the details: automation; equipment, licenses, and tools; other things which add to non-code technical debt; sunken cost fallacy
- Jeff Nyman: Stories from a Software Tester (blog) – agile testing, specialist testers, AI, etc.
- James Bach: Articles – “Good Enough” testing, Exploratory Testing etc.)
- Michael Bolton: DevelopSense: Articles, Blog posts
- Aaron Hockley: Kwality Rules – blog
- AgileSparks: Test-First Reading List
- AgileSparks: Agile Testing Reading List
- Friendly Tester: White Board Testing (intro, Youtube channel) – idea is to put out short 5-10 min vids having “relevant info on testing”
- Twitter: #Testing
- Twitter: #TestData
- Twitter: #TestAutomation

{kind=link}